Recently looked up some old Google articles / papers, found that Google has a number of systems on the design of the text are written planet scale, the breath that is really big. When you think about it, FAANG can do business to the global Internet companies, in addition to these five, there are not many other, they do have the capital to blow planet scale. Really envious.
Google’s employees came out to start a business, the company name is also TailScale (seems to be doing vpn’s), PlanetScale (this seems to be taking vitess out to start a business) so that means ex-googler is also more like the culture of this company.
This paper is a summary of Google’s 2015 publication “Reliable Cron across the Planet” on acm queue, which was later included in Chapter 24 of the famous book “Site Reliability Engineering” under a new convergent name: Distributed periodic Scheduling.
Why doesn’t standalone cron work?
Many people may not understand, since linux cron is so good, why do we need to make a distributed cron system?
Timed tasks are still a common requirement in companies.
- For the big data platform, we need to execute a timed task once an hour to import the logs generated by the online system into the hive (partitioned by hour).
- Operation scenario, some activities are timed to start, some e-commerce shopping festival, such as 618, double 11, activities from 00:00:00 to start, so at 00:00:00 hours need to be prepared before the event page put out for users to grab, let people come to these operations is very anti-human.
- Some platforms have deviations in the rules of awarding penalties, and when users complain, they need to erase the previous records of awarding penalties and restore the user’s score. The logic is simpler, scanning the MySQL table of new reasonable complaints every five minutes and executing the corresponding compensation logic.
- The game platform has matching requirements, and we need to kick those hanging users off the server regularly, which requires scanning the status of the full number of online users every 15 minutes.
To meet these needs, the most intuitive idea is that we manage these timed tasks in linux crontab, configuring these cron tasks on a separate server:
- (*) myserver-crontab
- myserver-service-1
- myserver-service-2
- myserver-service-3
The growth of the business will lead to more and more of these timed tasks, and when the crontab machine hangs, all the timed tasks will fail. If it happens that these cron tasks are not backed up, it’s time for the classic dumping session.
The probability of failure of a single machine is high, so there should be at least one independent cron service to ensure that when a single machine fails, the timed tasks are not lost and can still be executed.
How to design such a service
The text does not mention what system the cron task itself is stored in, but we can simply speculate on this, more complex business, probably thousands to tens of thousands of cron tasks, and changes will not be particularly frequent, configuration files, configuration systems, external storage (in Google’s words, is spanner up), should be able to.
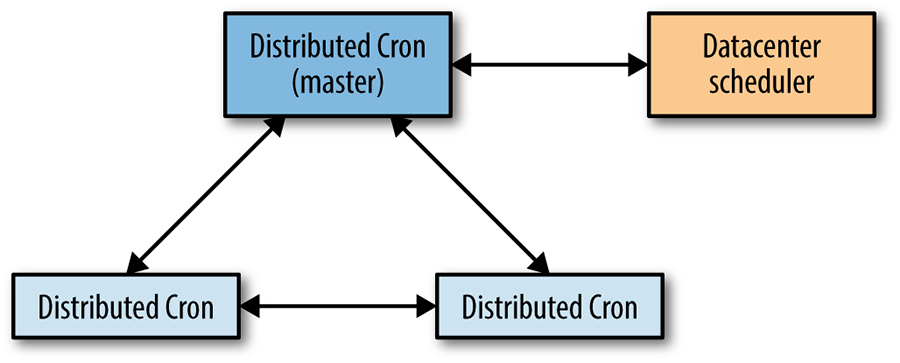
To avoid single machine failure, cron services use the paxos protocol to form a paxos cluster. The leader does the status updates and execution of cron tasks.
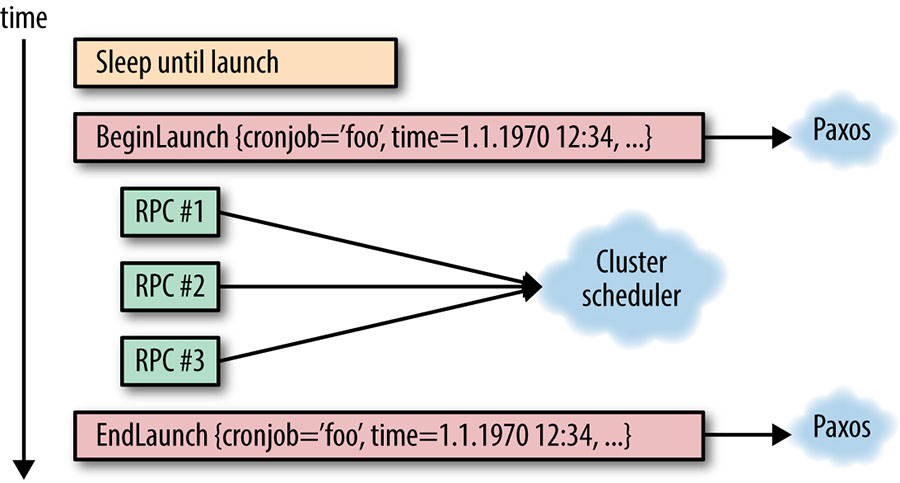
Task execution is decoupled from cron itself, so a cron task is typically executed by sending an RPC request to the datacenter scheduler. Each task requires two pieces of data, one for begin and one for end, which need to be synchronized in the paxos cluster because they are the key state information of the cron task.
Once a leader in a paxos cluster loses its leader status, it should no longer have any interaction with the datacenter scheduler.
Since a cron task will communicate with the scheduler multiple times during execution, a partial failure may occur (e.g. RPC #1, RPC #2 all complete, but a leader switch occurs in paxos before RPC #3 starts. In this case, there are two solutions.
- The newly elected leader needs to know if all previous RPCs have completed, and this requires the ability to query the status of these tasks externally. This process is tied to a specific infrastructure implementation within the company.
- Implement all external RPCs as idempotent requests, so that the new leader can simply send RPC #1, RPC #2, and RPC #3 again after taking over.
The idempotent of the external system, which requires the user’s task execution logic to cooperate, is also not particularly well done.
Other issues
Because paxos is a consistency algorithm based on logs, the stored logs themselves will continue to expand, and this process requires consideration of log compression, such as snapshot to replace the previous logs. This idea is similar to the snapshot in event sourcing.
Both the logs and snapshots are kept in local storage, while the snapshots are backed up in remote distributed storage. If the whole system crashes, the snapshot can be used to restore the service.
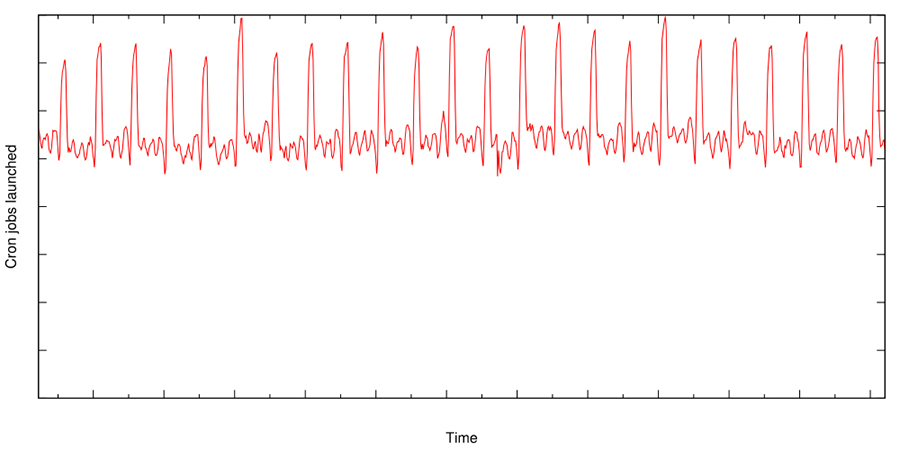
The large cron system itself also has some load imbalance problems, Google in the design process to cron to do a simple extension, the specific time configuration position can directly write a question mark, indicating that any time can be, so that the cron system can be based on the load to dynamically select the specific execution time of the task, the peak load to break up. Despite this, theoretically there will still be spikes in cron-related load, due to the nature of timed tasks.
Summary
Google’s cron design is still slightly complex, and we can make a relatively simple system if we sacrifice some of the dependency requirements.
Of course, everyone has k8s now, so perhaps for most companies, a straightforward cronjob using k8s would be sufficient.
Reference https://xargin.com/google-cron-design/